Projects
-
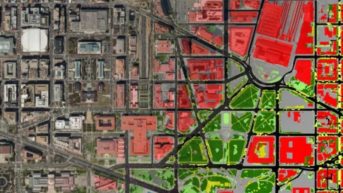
Applying computer vision and machine learning for land cover mapping.
-
Batch normalization has been widely used to improve optimization in deep neural networks. While the uncertainty in batch statistics can act as a regularizer, using these dataset statistics specific to the training set impairs generalization in certain tasks. Recently, alternative methods for normalizing feature activations in neural networks have been proposed. Among them, group normalization has been shown to yield similar, in some domains even superior performance to batch normalization. All these methods utilize a learned affine transformation after the normalization operation to increase representational power. Methods used in conditional computation define the parameters of these transformations as learnable functions of conditioning information. In this work, we study whether and where the conditional formulation of group normalization can improve generalization compared to conditional batch normalization. We evaluate performances on the tasks of visual question answering, few-shot learning, and conditional image generation.
-

In the interpretability literature, attention is focused on understanding black-box classifiers, but many problems ranging from medicine through agriculture and crisis response in humanitarian aid are tackled by semantic segmentation models. The absence of interpretability for these canonical problems in computer vision motivates this study. In this study we present a user-centric approach that blends techniques from interpretability, representation learning, and interactive visualization. It allows to visualize and link latent representation to real data instances as well as qualitatively assess strength of predictions. We have applied our method to a deep learning model for semantic segmentation, U-Net, in a remote sensing application of building detection. This application is of high interest for humanitarian crisis response teams that rely on satellite images analysis. Preliminary results shows utility in understanding semantic segmentation models, demo presenting the idea is available online.
-
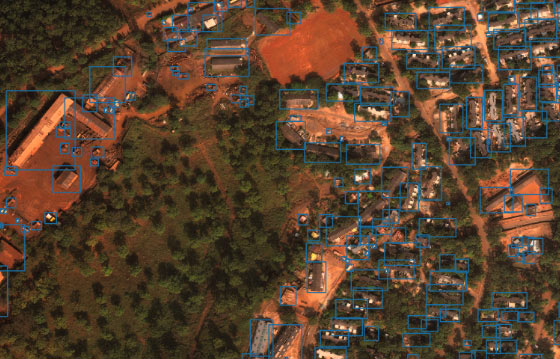
Applying computer vision to overhead imagery has the potential to detect emerging natural disasters, improve response, quantify the direct and indirect impact — and save lives. A VLL team is working on this challenge.
-

We present the first study of constructing adversarial examples for non-RGB imagery, and show that non- RGB machine learning models are vulnerable to adversarial. We propose a framework to make non-RGB image-based semantic segmentation systems robust to adversarial attacks. examples.
-
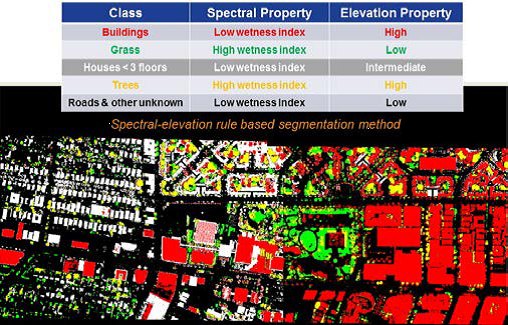
We propose Integrated Learning and Feature Selection (ILFS) as a generic framework for supervised dimensionality reduction. We demonstrate ILFS is effective for dimensionality reduction of multispectral and hyperspectral imagery, and significantly improves performance on the semantic segmentation task for high dimensional imagery.
We work on finding spatial feature correspondence between images generated by sensors operating in different regions of the spectrum, in particular the Visible (Vis: 0.4-0.7 um) and Shortwave Infrared (SWIR: 1.0-2.5 um). Under the assumption that only one of the available datasets is geospatial ortho-rectified (e.g., Vis), this spatial correspondence can play a major role in enabling a machine to automatically register SWIR and Vis images, representing the same swath, as the first step toward achieving a full geospatial ortho-rectification of, in this case, the SWIR dataset.